




 Artikel
Artikel

Aktives GUI-Element
Statisches GUI-Element
Quelltext
WPS-Objekt
Datei/Pfad
Befehlszeile
Inhalt Eingabefeld
[Tastenkombination]
OS/2 und mehrsprachige Zeichensätze
Teil 3
Dieser Artikel ist der dritte aus meiner Serie, in der ich einige Probleme mit OS/2 und der Behandlung von internationalen Texten bearbeite. Diese Ausgabe befaßt sich mit den Texten aus dem Internet und zeigt, wie bestimmte Anwendungen damit umgehen.
Also, Sie sehen sich eine e-Mail-Nachricht oder Webseite an, die lustige Zeichen enthält, von denen Sie wissen, daß sie nicht richtig sind, und sie würden nun diese gerne so sehen, wie der Autor sie eingegeben hat. Oder vielleicht beschweren sich Ihre e-Mail-Gegenüber, daß Ihre Nachrichten jede Menge unlesbarer Zeichen beinhalten. Oder vielleicht fragen Sie sich einfach nur, was ein ‘Zeichensatz’ ist und wie der funktioniert.
Dieser Artikel behandelt diese und andere Fragen.
Zeichensätze
Die meisten Internetdokumente, wie e-Mail-Nachrichten, Newsgruppenmeldungen und Webseiten, verwenden etwas, daß sich Zeichensatz-Kennung nennt. Das ist letztlich ein Parameter, der Ihrem Mailclienten, Newsreader oder Webbrowser mitteilt, welche Zeichenkodierung (oder welchen Zeichensatz) die Datei verwendet.
In einem HTML-Dokument ist die Zeichensatzkennung irgendwo in der Nähe des Dateianfangs (in dem <head> Abschnitt), üblicherweise als Bestandteil einer Zeile wie diese:
<meta http-equiv="Content-Type" content="text/html; "charset=iso-8859-1">
In einer e-Mail-Nachricht oder einer Newsgruppemmeldung ist die Zeichensatzkennung Bestandteil des Nachrichtenkopfs; ein typisches Beispiel sieht etwas so aus:
Content-Type: text/plain; charset=ISO-8859-1
In beiden Fällen ist die Zeichensatzkennung Bestandteil des Content-Type-Kopfes, der — wie man sehen kann — weitere wichtige Informationen zur Eigenschaft der Datei enthält.
Es ist wichtig sich einzuprägen, daß Internetnachrichten und Webseiten mit Zeichensätzen arbeiten und nicht mit Zeichenumsetztabellen. Obwohl sich beide Begriffe recht ähnlich sind, ist ein Zeichensatz eine standardisierte Zeichenkodierung, wogegen eine Zeichenumsetztabelle eine spezifische Umsetzung eines solche Zeichensatzes ist. Also, während OS/2 den Zeichensatz ISO-8859-1 mit der Zeichenumsetztabelle 819 implementiert, können andere Betriebssysteme oder andere Softwareumgebungen andere Mechanismen verwenden. (Tatsächlich, wie ich im ersten Teil erwähnte, implementiert Windows 95 diesen als Untermenge der wesentlich erweiterten Zeichenumsetztabelle 1252; die Windows NT-Familie verwendet Unicode für alle Textumsetzungen, weshalb viele verschiedene Zeichensätze nebeneinander unterstützt werden können).
Jedoch — zumindest unter OS/2 — nutzt Ihre Software tatsächlich die Zeichensatzkennung um herauszufinden, welcher Zeichensatz zur Anzeige der Datei verwendet werden soll.
Kodierungsübersetzungen
Ich habe in meinen beiden letzten Artikeln die Zeichenumsetztabellen recht ausführlich beschrieben — insbesondere wie man anders kodierte Dokumente durch Umschalten auf eine geeignete Zeichenumsetztabelle anzeigen lassen kann. Aber, wie ich auch erwähnte, sind mit dem hin- und herspringen zwischen den Zeichenumsetztabellen auch einige Probleme verbunden.
Was ich jedoch bislang noch nicht angesprochen hatte, ist die andere wichtige Verwendung von Zeichenumsetztabellen: als Übersetzungstabellen, um tatsächlich eine Textkodierung in eine andere umzuwandeln.
Mit Umwandeln meine ich die Änderung des Datenstroms selber: Übersetzen eines Zeichens aus einer Zeichenumsetztabelle in das entsprechende Zeichen in einer anderen Tabelle.
Als Beispiel nehmen wir die Zeichenfolge, die ich schon im ersten Teil verwendet habe:We stopped for lunch at a café in Reykjavík.
Nehmen wir mal an, wir hätten diesen Text (vielleicht in einer e-Mail) kodiert mit Zeichenumsetztabelle 1252 erhalten, aber unser System ist auf Zeichenumsetztabelle 850 eingerichtet. Ohne jeden Eingriff würde die Zeichenfolge auf unserem Bildschirm in etwa so angezeigt:
We stopped for lunch at a cafÚ in ReykjavÝk.
Anstatt nun eine richtige Darstellung durch Umschalten der Zeichenumsetztabelle auf 1252 oder 1004 zu erhalten (wie wir es im ersten Teil gemacht haben), haben wir Techniken zur Verfügung, die es uns gestatten, diesen Text tatsächlich umzuwandeln, so daß er für die Zeichenumsetztabelle 850 richtig geschlüsselt ist.
Wenn der originale Text für die Zeichenumsetztabelle 1252 geschlüsselt wurde, sehen die nackten Byte-Werte so aus:
57 65 20 73 74 6F 70 70 65 64 20 66 6F 72 20 6C 75 6E 63 68 20 61 74 20 61 20 63 61 66 E9 20 69 6E 20 52 65 79 6B 6A 61 76 ED 6B 2E
Die Umwandlung des Textes auf Zeichenumsetztabelle 850 resultiert in den folgenden geänderten Byte-Werten:
57 65 20 73 74 6F 70 70 65 64 20 66 6F 72 20 6C 75 6E 63 68 20 61 74 20 61 20 63 61 66 82 20 69 6E 20 52 65 79 6B 6A 61 76 A1 6B 2E
Die hervorgehobenen Byte-Werte sind die, die geändert werden müssen (sie stehen für die nicht Standard-ASCII-Zeichen é und í).
Lassen wir uns die Zeichenfolge nun anzeigen, wird sie richtig angezeigt, obwohl wir — und das ist der ausschlaggebende Punkt — immer noch Zeichenumsetztabelle 850 zur Anzeige verwenden.
Was wir gemacht haben, ist hier den Text so zu ändern, daß er der Zeichenumsetztabelle entspricht; eigentlich ist das ziemlich genau das Gegenteil dessen, was wir in den beiden ersten Artikeln gemacht haben, wo wir die Zeichenumsetztabelle so geändert haben, daß sie dem Text entspricht. Wenn man allerdings diesen Weg einschlägt, erhält man folgende Vor- und Nachteile:
Vorteile
- Durch das Umsetzen des Textes in die Systemzeichenumsetztabelle kann dieser zwischen zwei Programmen ausgetauscht werden (zum Beispiel unter Verwendung der Zwischenablage) ohne daß jedes Ziel-Programm seine Zeichenumsetztabelle umschalten muß.
- Man vermeidet die gelegentlichen Fehler unter OS/2, die mit dem Umschalten des Anzeigezeichensatzes einhergehen.
- Die Zeichen können auch in Textmode-Sitzungen richtig angezeigt werden - vorausgesetzt die aktuelle Prozeßzeichenumsetztabelle unterstützt diese Zeichen (siehe auch “Nachteile”).
Nachteile
- Der hauptsächliche Nachteil ist, daß Zeichen, die unter der Ziel-Zeichenumsetztabelle nicht existieren, nicht umgesetzt werden können und daher verlorengehen. Zum Beispiel: kyrillische Zeichen gibt es in der Zeichenumsetztabelle nicht, und daher, wenn Sie einen Text umwandeln, der solche Zeichen enthält, werden diese durch ein generisches Ersatzsymbol dargestellt (meist das 'Haus'-Zeichen, ⌂, obwohl dies von der Zeichenumsetztabelle abhängt).
Wie aber führen wir eine solche Umsetzung aus? Nun, das ist etwas, was normalerweise auf Anwendungsebene passiert: mit anderen Worten, Ihr Webbrowser, e-Mailclient oder Newsreader wird das mutmaßlich für Sie zu tun. Soweit die Theorie, wie auch immer; natürlich, einige Anwendungen sind mehr (oder weniger) intelligenter als andere.
Zeichensatzunterstützung in Anwendungen
Dieser Abschnitt befaßt sich damit, wie einige wenige Programme der Unterstützung von verschiedenen Zeichensätzen gerecht werden.
Mozilla
Die verschiedenen Mozilla-Produkte haben unbestritten die beste Zeichensatzunterstützung aller Internet-Applikationen, die für OS/2-Anwender verfügbar sind. Mozilla behandelt, und rendert, anscheinend alle Texte als Unicode. Da Unicode, theoretisch, alle Zeichensätze unterstützt, sollten Zeichen durch Konvertierung nicht verlorengehen. Und aufgrund der deutlichen Entwicklungsanstrengungen, die Mozilla erhalten hat, ist sichergestellt, daß seine verschiedenen Produkte eine weite Auswahl von verschiedenen Zeichenkodierungen unterstützt, wie Sie es möglicherweise gehofft haben.
Mit Mozilla ist die Unterstützung der verschiedenen Zeichensätze ziemlich lückenlos. Hin und wieder mögen Sie eine Webseite finden, die ihren Zeichensatz nicht richtig mitteilt, weshalb Sie in solchen Fällen Mozilla mitteilen müssen, welche Zeichenkodierung anzuwenden ist (über Ansicht > Zeichenkodierung-Menü, wie letztes Mal beschrieben), aber das kommt ziemlich selten vor.
Unter Mozilla ist die Zeichensatzunterstützung im Grunde nur durch die von Ihnen eingesetzten Schriftarten begrenzt. Unicodefähige Schriftarten sind generell zu empfehlen (besonders für die “Weitere Sprachen”-Kategorie). Die Konfiguration der Schriftarten in Mozilla wurde im zweiten Teil dieser Serie beschrieben.
Es gibt da einen möglichen Stolperstein in Mozilla, an den Sie denken müssen. Damit Sie in den Genuß der vollständigen Zeichenunterstützung gelangen, müssen alle nachfolgend genannten Voraussetzungen erfüllt sein:
- Die Innotek-Font-Engine muß installiert sein.
- Die richtigen und vollständigen Einträge für die Font-Engine und alle Mozilla-Applikationen müssen in der Registry im HKEY_CURRENT_USER\Software\Innotek-Zweig eingetragen sein. Achten Sie besonders darauf, da die letzten Versionen der Font-Engine diesen Zweig nicht mehr wie gehabt anlegen (diese Einträge werden statt dessen unter HKEY_LOCAL_MACHINE gemacht). Sie müssen daher die richtigen Werte selber in der Registry hinterlegen.
- Die folgende Umgebungsvariable muß gesetzt sein:
SET MOZILLA_USE_EXTENDED_FT2LIB=T.
Es ist leicht möglich, daß eine oder mehrere dieser Voraussetzung(en) nicht erfüllt werden; eine unvollständige Konfiguration offenbart sich dadurch, daß Fremdsprachenzeichen (insbesondere ostasiatische) als Rechtecke gerendert werden.
Pronews/2
Die neuesten Versionen von Pronews/2 können eine beachtliche Anzahl an verschiedenen Zeichensätzen handhaben. Leider wird es etwas unübersichtlich, wenn man verstehen will, wie die einzelnen Stücke zusammenpassen.
Im Gegensatz zu Mozilla ändert Pronews/2 die Anzeigezeichenumsetztabelle nicht, wenn Texte wiedergegeben wird; statt dessen (in Ermangelung an Hilfskonstruktionen wie CPPal) muß der Text in eine einzelne, vorgegebene Zeichenumsetztabelle umgewandelt werden - üblicherweise die Zeichenumsetztabelle, in der Pronews selber gerade läuft. (Dies liegt zum Teil daran, daß Pronews sehr viel mehr auf nativen PM controls aufbaut, die wiederum an einigen Beschränkungen in Sachen Zeichenumsetztabellenunterstützung leiden.)
Was Pronews macht, ist konzeptionell einfach und geradeaus: Er überprüft für jeden Artikel, den Sie gerade lesen, den Zeichensatz und wandelt dann den Artikeltext in die aktuelle Zeichenumsetztabelle. Im umgekehrten Falle, beim Nachrichtenschreiben, interpretiert er den Artikeltext gemäß der gültigen Zeichenumsetztabelle und wandelt diesen dann in den Zeichensatz, den Sie aktiviert haben.

Bild 1: Konfiguration der Zeichensatzunterstützung in Pronews/2
Das Verhalten wird dadurch bestimmt, wie Sie bestimmte Konfigurationsoptionen gesetzt haben. Diese Optionen finden Sie auf Seite 8 der Gruppeneinstellungen (siehe Bild 1), und diese können entweder allgemein oder auf einer Per-Newsgruppen-Basis eingestellt werden.
- Verschlüsselungsmethode
- Diese Einstellung betrifft den Zeichensatz eigentlich nicht; es gibt nur an, ob 8-Bit-Zeichen wortgetreu gesendet oder ob sie einfach verschlüsselt werden, um sie sicher an 7-Bit Relais zu übergeben (diese sind heutzutage sehr selten geworden). Im allgemeinen kann man diese Einstellung auf dem Standard belassen.
- Anzeigestandard
- Diese Einstellung legt fest, wie einkommende Nachrichten behandelt werden, die ihren Zeichensatz nicht angeben. Für solche Nachrichten wird derjenige Zeichensatz angenommen, den Sie hier angeben; entweder “US-ASCII” oder “Windows-1252” sind gewöhnlich eine gute Wahl.
- Zeichenumsetztabelle
- Diese Einstellung teilt Pronews mit, in welche Zeichenumsetztabelle der Text zur Anzeige gewandelt werden soll (so daß Sie ihn richtig lesen können).
Im Regelfall sollten Sie dies auf “Current” belassen, was bedeutet, daß jeder Text in die Anzeigezeichenumsetztabelle gewandelt wird (oder aus ihr heraus beim Senden).
Wenn sie eine andere Zeichenumsetztabelle wählen, kann es sein, daß Sie den Text nicht mehr richtig lesen können; jedoch kann dies sinnvoll sein, wenn Sie den Text von oder in einer anderen Software kopieren oder einfügen, wenn diese eine andere Zeichenumsetztabelle zur Anzeige verwendet.
- Senden
- Diese Einstellung teilt Pronews mit, welchem Zeichensatz Sie alle Ihre Nachrichten versenden wollen. Im allgemeinen sollten Sie einen Zeichensatz wählen, der alle Zeichen unterstützt, die sie jemals in Ihren Nachrichten zu verwenden gedenken. ISO-8859-1 oder ISO-8859-15 sind eine gute Wahl, wenn Sie ausschließlich Nachrichten in Latein basierten Sprachen versenden wollen; UTF-8 wäre zu bevorzugen, wenn Sie eine größere Auswahl an Sprachen annehmen können.
Wichtig ist dabei nicht zu vergessen, daß Sie Texte nur lesen — oder schreiben — können, soweit diese von der eingestellten Zeichenumsetztabelle unterstützt werden. Jedes nicht unterstützte Zeichen wird dabei in ein allgemeines Ersatzsymbol umgewandelt. Zudem gilt, wenn die eingestellte Zeichenumsetztabelle nicht mit der aktuellen Anzeigezeichenumsetztabelle übereinstimmt (oder zumindest damit kompatibel ist), werden nicht ASCII-Zeichen kaum in lesbarer Form auf Ihrem Bildschirm erscheinen, obwohl Sie bei Ihrem Korrespondenz-Gegenüber richtig angezeigt werden sollten.
Die neueste Ausgabe von Pronews erlaubt Ihnen sogar die Liste der verfügbaren Zeichensätze und Zeichenumsetztabellen zu modifizieren, indem Sie einige ASCII-Konfigurationsdateien im Programmverzeichnis bearbeiten.
- Ihre aktuelle Zeichenumsetztabelle (mit der Pronews läuft) muß in der Datei CODEPAGE.PN gelistet sein — die meisten gebräuchlichen Zeichenumsetztabellen sind bereits verzeichnet. (Diese Datei legt auch fest, welche Zeichenumsetztabellen unter Zeichenumsetztabelle in den Pronews-Einstellungen, siehe oben, angezeigt werden.)
- Damit ein Zeichensatz unterstützt wird, muß er direkt mit einer OS/2-Zeichenumsetztabelle übereinstimmen. Der Zeichensatzname muß in der Datei CHARSET.PN verzeichnet sein und die Zeichensatz-zu-Zeichenumsetztabelle-Zuordnung muß in der Datei CPALIAS.PN angelegt sein.
Weitere Informationen entnehmen Sie der README.TXT-Datei von Pronews.
PMMail/2
Die Version 2.x von PMMail/2 hat nur eine ziemlich rudimentäre Zeichensatzunterstützung. Es weiß, wie es ein paar wenige übliche Ein-Byte-Zeichenumsetztabellen (unter anderem 437, 850, 862 und 864) erkennt und etwa ein Dutzend übliche Zeichensätze (US-ASCII, KOI8-R und ISO-8859-1 bis -10). Es verwendet die aktuelle aktive Zeichenumsetztabelle um Text in den gewählten Zeichensatz zu übersetzen, wenn Nachrichten versendet werden, und es übersetzt vom erkannten Zeichensatz in die aktuelle Zeichenumsetztabelle, wenn Nachrichten betrachtet werden.
Das funktioniert auch recht gut, wenn Ein-Byte-Zeichenumsetztabellen in eine Ein-Byte kodierte Nachricht umgewandelt werden (und umgekehrt). Es unterstützt jedoch keine modernen Zeichensätze (wie etwa Windows-1252 oder ISO-8859-15) und ist nicht geeignet für Multi-Byte-Kodierungen (wie etwa UTF-8, EUC oder Shift-JIS).
Zum Glück wird demnächst eine neue Version von PMMail/2 (nun von VOICE gewartet) erscheinen, und dessen Zeichensatzunterstützung wurde wesentlich verbessert und erweitert.
Egal welche PMMail-Version, die grundlegende Logik ist nahezu gleich. Das globale Einstellungsnotizbuch hat eine Seite, die mit Locale betitelt ist (siehe Bild 2), auf welcher man den standardmäßigen Zeichensatz zum Versenden von Nachrichten angibt.
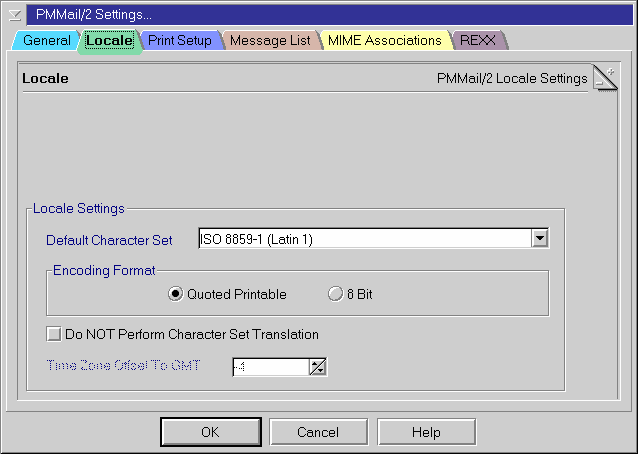
Bild 2: Konfiguration der Zeichensatzunterstützung in PMMail/2
(Bild von Version 2.20)
- Standard-Zeichensatz
- Wie gesagt, PMMail verwendet diese Auswahl, um den Zeichensatz der abgehenden Nachrichten festzulegen.
(In PMMail Version 3 wird dies auch zur Standardanzeige von eingehenden Nachrichten verwendet, wenn diese ihren Zeichensatz nicht ordnungsgemäß mitteilen; Version 2.x schaltet einfach auf US-ASCII, wenn ein Zeichensatz unbekannt ist.)
- Verschlüsselungsformat
- Das ist gleichwertig zur Pronews “Verschlüsselungsmethode”-Einstellung. Es gibt an, ob nicht ASCII-Zeichen für die 7-Bit-Relais verschlüsselt werden sollen oder nicht.
Die Auswahl "Quoted Printable" ist meistens die beste Option.
- KEINE Zeichensatzübersetzung durchführen
- Diese Einstellung schaltet die Übersetzung zwischen den Zeichenumsetztabellen und Zeichensätzen ab, was bedeutet, daß PMMail annimmt, daß der zu versendende
oder anzuzeigende Text bereits richtig kodiert ist.
Diese Option kann recht nützlich sein, wenn Sie Text in eine abgehende Nachricht einfügen wollen, der bereits in dem gewählten Zeichensatz vorliegt (aber nicht in der eingestellten Zeichenumsetztabelle).
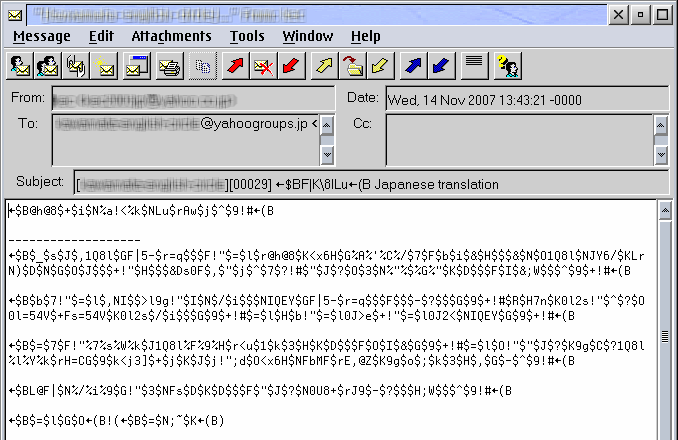
Bild 3: Nicht unterstützter japanischer Text (Zeichensatz ISO-2022-JP) in PMMail/2
Wie schon Pronews ist auch PMMail darauf beschränkt, nur Texte in denjenigen Zeichenumsetztabellen anzuzeigen, in denen es selber läuft. Auch hier liegt es daran, daß PMMail native PM controls verwendet, die im Umgang mit mehreren Zeichenumsetztabellen sehr eingeschränkt sind. Unter bestimmten Umständen kann man jedoch das CPPal-Werkzeug einsetzen (wie im ersten Teil dieser Serie beschrieben) um die Zeichenumsetztabelle für PMMail zu ändern, bevor es die anzuzeigende Nachricht öffnet, damit man Nachrichten in einer nicht aktiven Zeichenumsetztabelle lesen kann.
Bild 3 zeigt ein typisches Beispiel eines japanisch kodierten Textes (unter Verwendung des üblichen Zeichensatzes ISO-2022-JP), so wie er in PMMail 2.20 erscheint - das diese Kodierung nicht unterstützt. (Ich habe ein paar Sachen ausradiert, zum Schutz der Privatsphäre.) Wie man erkennen kann, wird es als unverständliches Kauderwelsch abgebildet. In diesem bestimmten Fall würde auch ein Umschalten der Zeichenumsetztabelle mit CPPal oder etwas Vergleichbarem nicht helfen, da keine Zeichenumsetztabelle vorhanden ist, die den Zeichensatz ISO-2022-JP implementiert (das ist eine modale Kodierung basierend auf Escape-Sequenzen, die gezielt durch die jeweilige Applikation unterstützt werden muß. Anmerkung des Übersetzers: Nach Rücksprache mit dem Autor hier ein kurzer Klärungsversuch zum Begriff der modalen Kodierung: Modale Kodierung bedeutet, daß in ISO-2022-JP einige Kodierungen wie in einem lateinischen Zeichensatz belegt sind, andere jedoch nicht. Dies wird durch entsprechende Escape-Sequenzen gesteuert. Es wird also in dem Zeichensatz ein lateinischer und ein japanischer Modus unterstützt, ggf. auch noch weitere Modi. Dieses ist eine eher ungewöhnliche Implementierung eines Zeichensatzes, da hier eine feste Zuordnung zwischen Kode und Zeichen, wie für Zeichenumsetztabellen üblich, nicht funktioniert. Die jeweilige Applikation muß in Abhängigkeit des Modus zwischen verschiedenen Darstellungen eines Zeichens "intelligent" unterscheiden).
In PMMail 3.x wird die Unterstützung für ISO-2022-JP (neben anderen Zeichensätzen) mitgeliefert, so daß die Kodierung solcher Nachrichten nun unterstützt werden sollte. Jedoch wird PMMail nur dann japanische Zeichen anzeigen können, wenn die aktuelle Zeichenumsetztabelle dies unterstützt. Bild 4 zeigt, wie die Nachricht im neuen PMMail erscheint, wenn man eine nicht japanische Zeichenumsetztabelle, wie etwa 850, verwendet.

Bild 4: Unterstützter aber nicht darstellbarer japanischer Text in PMMail 3.
Zu bemerken ist, daß alle nicht unterstützten Zeichen in der Nachrichtenanzeige durch das “Haus”-Symbol (⌂) ersetzt wurden. Dies ist das standardmäßige Ersatzzeichen in der Zeichenumsetztabelle 850, die ich verwendete, als ich das Bildschirmfoto gemacht habe.
Das Ersatzzeichen welches in der Zeichenumsetztabellenkonvertierung verwendet wird, und oben beschrieben ist, darf nicht mit dem Ersatz-Glyphen den speziele Schriftarten mitbringen, wie im ersten Teil dieser Serie beschrieben, verwechselt werden.
Das Zeichenumsetztabellen-Ersatzzeichen ist, wie der Name schon sagt, eine Funktion der Zeichenumsetztabelle. Der Zweck ist, ein Zeichen, das einen bekannten Wert hat, aber von der aktuellen Zeichenumsetztabelle nicht unterstützt wird, darzustellen. Das Haus-Symbol (⌂) wird weithin dafür eingesetzt, obwohl es auch das Kästchen (☐), ein Fragezeichen (?) oder auch das Unicode-Ersatzzeichen (�) sein kann (Dies ändert sich mit der Zeichenumsetztabelle und kann auch durch die Applikation überschrieben werden).
Der Schriftarten-Ersatzglyph auf der anderen Seite ist spezifisch für die jeweilige Schriftart und kann nicht übersteuert werden. Er wird dann eingesetzt, wenn Zeichen dargestellt werden müssen, die durch die Schriftart aus verschiedenen Gründen nicht darstellbar sind. (Dies kann daran liegen, daß die Schriftart keinen Glyphen für dieses Zeichen enthält oder weil das Zeichen an sich nicht darstellbar ist, oder weil der Zeichenwert selbst irgendwie ungültig ist.) ☐ und � werden beide recht häufig eingesetzt, wie auch andere unsinnige Schnörkeleien.
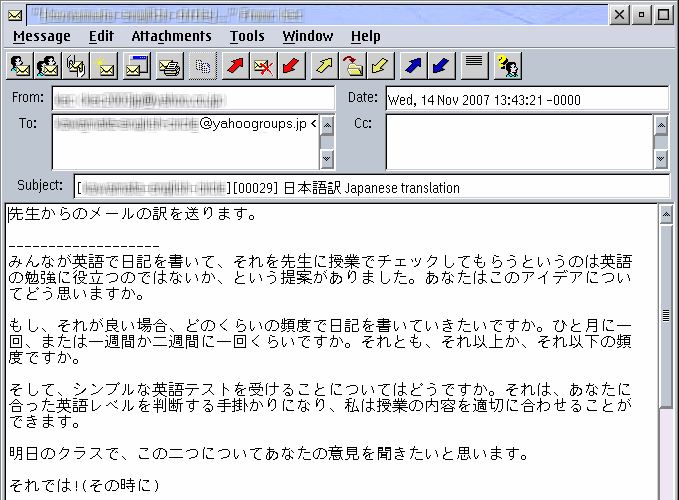
Bild 5: Unterstützter und darstellbarer japanischer Text in PMMail 3.
Will ich die Zeichen so sehen, wie der Absender es gewollt hat, muß ich die aktuelle Zeichenumsetztabelle auf ein solche abändern, die das unterstützt. Da ich weiß, daß der Text in Japanisch geschrieben wurde (was sich leicht herausfinden läßt, wenn man im Nachrichtenkopf nachschaut, welcher Zeichensatz angegeben ist), beende ich PMMail zunächst und lasse es dann mit der Zeichenumsetztabelle 932 laufen, weil dies die OS/2-japanische Zeichenumsetztabelle ist. (Hätte ich auf eine andere Ein-Byte-Zeichenumsetztabelle wechseln wollen, hätte ich einfach CPPal einsetzen könne, ohne PMMail beenden zu müssen; aber, wie ich letztes Mal erwähnte, das Umschalten von einer Ein-Byte-Zeichenumsetztabelle zu einer Doppel-Byte-Zeichenumsetzabelle funktioniert über diesen Weg nicht sonderlich gut.)
Nun, wenn ich die Nachricht unter der Zeichenumsetztabelle 932 öffne und sichergestellt ist, daß eine japanisch fähige Schriftart verfügbar ist, sehe ich die Nachricht so, wie in Bild 5 gezeigt.
Bedenken Sie, daß das gleiche Problem besteht (nur umgekehrt), wenn Sie eine Nachricht schreiben wollen: Sie können nur solche Zeichen eingeben, die auch von der aktuellen Zeichenumsetztabelle unterstützt werden. Wenn dann auf “Senden” klicken, wird der Nachrichtentext in den Zeichensatz umgewandelt, den Sie dafür vorgesehen haben. Selbstverständlich sollten sie daher einen Zeichensatz auswählen, der die Zeichen unterstützt, die Sie gerade eingegeben haben (das Thema behandle ich gleich).
Dies fördert einen ziemlich fiesen Fallstrick zutage, nämlich, wenn man auf eine Nachricht antwortet oder diese weiterleitet, zitiert man den Text mit den enthaltenen, durch die Zeichenumsetztabelle nicht unterstützten Zeichen, und diese Zeichen werden in die Ersatzzeichen umgewandelt und sind verloren. Zum Beispiel, wenn ich (aus welchem Grund auch immer) meine Zeichenumsetztabelle auf 850 zurücksetze und dann auf die Nachrichten aus den Bildern 3 bis 5 antworte, wird jeder japanische Text, den ich zitiert habe, im Nachrichteneditor umgewandelt und durch die Ersatzzeichen ausgetauscht. Und im Unterschied zur empfangenen Nachricht (wo dies nur die Nachrichtenanzeige betrifft) bleiben Ersetzungen in abgehende Nachrichten permanent.
Die einfache Merkregel dazu lautet: Kann man zitierte Zeichen richtig lesen, bleiben sie erhalten wenn man antwortet oder weiterleitet (unter der Voraussetzung, daß der Zeichensatz diese unterstützt). Kann man die Zeichen im Nachrichteneditor nicht richtig lesen — also dann, wenn sie als Ersatzzeichen erscheinen — gehen sie verloren.
In aller Kürze: Stellen Sie sicher, daß Sie auf eine Nachricht mit der Zeichenumsetztabelle antworten, in der Sie den originalen Text richtig lesen können.
Wie schon gesagt, die neue PMMail-Version sollte bald veröffentlicht werden (mag sein, daß sie zu dem Zeitpunkt, an dem Sie den Artikel lesen, schon herausgegeben wurde). PMMail Version 3 unterstützt ein große Vielfalt an Zeichensätzen, einschließlich derer, die schon vorher unterstützt wurden:
- UTF-8
- ISO-8859-11 (Thai/TIS-620), ISO-8859-13 (Latin-7) und ISO-8859-15 (Latin-9)
- Windows-1250 bis Windows-1257
- ISO-2022 Internet Nachrichtenkodierung für Japanisch (-JP) und Koreanisch (-KR)
- Shift-JIS (PC-Ausführung der Kodierung für Japanisch)
- Extended Unix Code (Unix-Ausführung der Kodierung für Chinese, Japanese, und Koreanisch)
- BIG-5 (Taiwanesisch)
Auswahl eines Zeichensatzes
Alle oben beschriebenen Programme ermöglichen Ihnen einen Zeichensatz für alle abgehenden Nachrichten auszuwählen. Alle bieten zu diesem Zweck eine globale Einstellung an. In Mozilla und PMMail 3 kann man sogar den Zeichensatz individuell für jede einzelne Nachricht auswählen. Alle unterstützen eine große Auswahl an Zeichensätzen, womit sich die Frage stellt: Welchen Zeichensatz soll man verwenden?
Diese Frage kann man am besten beantworten, wenn man folgende 2 Faktoren bedenkt:
- Welche Art(en) von Zeichen müssen Sie in Ihren Nachrichten darstellen können? Zum Beispiel, wenn Sie Nachrichten in Russisch versenden müssen, müssen Sie einen Zeichensatz auswählen, der russischen Text unterstützt.
- Welche Zeichensätze können Ihre Korrespondenten (Briefpartner, oder besser, deren e-Mail-Software) verarbeiten? Natürlich hängt das von deren eigener Computereinrichtung ab. Die meisten der modernen e-Mail-Software können fast jeden Zeichensatz verarbeiten, den Sie benennen können, aber setzen sie eine Software ein, die schon ein paar Jahre alt ist, kann es zu Kompatibilitätsproblemen kommen. Sie müssen dann eine fundierte Einschätzung aufgrund Ihrer Kenntnis der in Frage kommenden Personen machen — oder es eben mit diesen diskutieren, wenn Sie Probleme vorhersagen können.
Nimmt man nur Punkt 1, dann ist logischerweise UTF-8 (Unicode) die erste Wahl, da sie nahezu alle denkbaren Zeichen aus nahezu allen Sprachen dieser Welt unterstützt. Allerdings kann nicht jede e-Mail-Software tatsächlich UTF-8 garantiert unterstützen, PMMail 2.x (und älter) ist ein gängiges Beispiel.
In der Konsequenz bedeutet dies, wenn man annimmt, daß die Korrespondenten ein Problem damit haben, daß dann ein älterer, weitgehend unterstützter Zeichensatz die womöglich bessere Wahl ist. Der prinzipielle Nachteil ist dann, daß die älteren Zeichensätze nicht so viele verschiedene Sprachen abdecken.
Einer der ältesten und am häufigsten benutzte Zeichensatz ist der ehrwürdige ISO-8859-1 (im ersten Teil dieser Serie beschrieben), der die meisten westeuropäischen Sprachen abdeckt und durch nahezu jedes existierende, bekannte e-Mail-Programm unterstützt wird. Für Nachrichten in Englisch, Deutsch, Französisch, Flämisch, Spanisch, Italienisch und anderen Sprachen sollte dies ein gute, vernünftige Wahl sein.
Aktualisierungen und Berichtigungen
Bevor ich nun zusamenfasse, möchte ich die Gelegenheit ergreifen und Aktualisierungen zu einigen Punkten aus den vorherigen Teilen vornehmen:
Im ersten Teil beschrieb ich einen lästige Fehler in OS/2, der dazu führen konnte, daß die Anzeige von nicht ASCII-Text mittels des Presentation Managers nicht mehr möglich war, wenn man die Anzeige-Zeichenumsetztabelle zu häufig hin- und hergeschaltet hatte. Es stellte sich heraus, daß es sich dabei um eine Art Resourcen-Leck in der PMMERGE.DLL handelte, und IBM hat nun dafür einen Fix bereitgestellt. Es ist anwendbar auf OS/2 4.5x-Systemen (einschließlich der mit den letzten Convenience Package FixPaks behandelten) und steht registrierten eComStation-Anwendern als APAR PJ31908 zur Verfügung. (Ich bedanke mich an der Stelle bei Chuck McKinnis für seinen beharrlichen Einsatz bei IBM, um dies gelöst zu kriegen - und natürlich bei den Leuten bei IBM, die das repariert haben!)
KO Myung-huns KShell-Programm wurde mehrfach aktualisiert, seitdem Teil 2 veröffentlicht war. Die gute Nachricht ist, daß es nun die Zwischenablage (nur Text) unterstützt, wodurch der Nutzen deutlich zugenommen hat. Insgesamt hat auch die Stabilität zugelegt (die schlechte Nachricht ist, daß die letzten Versionen nicht mehr so gut mit der Innotek-Font-Engine zusammen funktionieren; aber das sollte kein großes Manko sein, wenn man damit einigen versteckten Schriften auf die Spur kommt).
Als letztes eine kurze Berichtigung im Teil 1: Ich unterstellte, daß die Unicode-Schriftart Arial Unicode MS ein Teil von Windows sei. Tatsache ist, daß diese mit MS Office (Office 97 und neuer) mitgeliefert wird und in das Windows Font-Verzeichnis kopiert wird, wenn bestimmte Office-Sprachauswahlen bei der Installation akzeptiert wurden.
Schlußbemerkungen
Bis hierher habe ich so ziemlich alle Grundlagen beschrieben, die man zum Einsatz der Zeichenumsetztabellen im Umgang mit unterschiedlich kodierten Texten unter OS/2 braucht. Wie man erkennen kann, ist das nicht immer ein so elegantes Verfahren wie man es sich wünscht, aber man kann damit nahezu alles machen, was erforderlich ist.
Wie ich schon im ersten Teil erwähnte, hat das gesamte Zeichenumsetztabellensystem eine große Schwäche, nämlich daß man nur jeweils einen (oder letztlich nur einen nicht englischen) Zeichensatz einsetzen kann. Schon vor einigen Jahren hat die Computerindustrie das Problem erkannt und kam mit einer intelligenten Lösung: dem Unicode-Standard.
Wie Sie mittlerweile festgestellt haben, hat eine sachgerechte Diskussion über Unicode in diesen Artikeln soweit nicht wirklich stattgefunden. Der Grund liegt darin, daß die Unicode-Unterstützung in OS/2, obwohl vorhanden, ziemlich obskur ist und von den jeweiligen Anwendungen abhängt. Infolgedessen ist dieses eher eine Angelegenheit für Programmierer als für den Anwender.
Nichtsdestotrotz gibt es da einige Aspekte aus Unicode zu wissen, die für jedermann brauchbar sind. Ich werde mich daran versuchen und in der Zukunft noch einen weiteren Artikel schreiben, um einige davon zu aufzugreifen.