




 Feature articles
Feature articles

Active GUI element
Static GUI element
Code
WPS object
File/Path
Command line
Entry-field content
[Key combination]
OS/2 and Multilingual Character Sets
Part 2
This article is the second in a series that discusses some of the issues involved in dealing with international text under OS/2. This installment focuses on viewing the double-byte text used in Asian languages such as Chinese, Japanese, and Korean.
In my last article, I described various techniques for viewing text in different single-byte character sets under OS/2. As I explained, when you need to view text in a character set that is not supported by your current system codepage, you can usually display it correctly by changing your codepage.
You can change the process codepage, the PM codepage, or both. Changing the process codepage works in a wider range of circumstances (for example, when printing); however, you can only set it to one of the (maximum) two codepages defined in your CONFIG.SYS. Changing the PM codepage only works in a GUI environment (and can occasionally stop working due to an obscure OS/2 bug [see part 1]), but has the advantage that you can access a huge range of codepages on the fly, without reconfiguring your system.
Both of these methods work reasonably well when dealing with traditional single-byte codepages, wherein a single byte corresponds to a single character.
But what happens when you have to deal with character sets that contain hundreds or thousands (or even tens of thousands) of unique characters, and a single byte's range of 256 possible values (or codepoints) is not sufficient to encode them all? This is particularly true of several East Asian writing systems: Chinese, Japanese, and Korean, the so-called CJK character sets.
As you might expect, the game changes considerably once a single byte is no longer sufficient to represent a single character.
DBCS and Multi-Byte Encoding
To handle such massive character sets, it becomes necessary to use two bytes to represent each character instead of one. This approach is known as double-byte character set (DBCS) encoding.
The problem, of course, is that you still need to maintain compatibility with existing data that is encoded using only one byte per character. This is achieved through a scheme that is usually referred to as multi-byte character encoding.
“Multi-byte encoding” implies that text may contain a mixture of single- and double-byte characters. (In fact, some encodings, such as UTF-8, allow triple- or even quadruple-byte characters as well.) This is sometimes also referred to as “variable-width encoding."
In some other contexts, usually programming references, you may see the term “multi-byte” used to refer to any data stream that uses byte-based character encoding (as opposed to encodings that use short or long integers to represent individual characters). This latter use of the term therefore covers single-byte encodings as well as variable-width ones.
For the purposes of this article, however, I am using the term “multi-byte” to refer specifically to variable-width encodings.
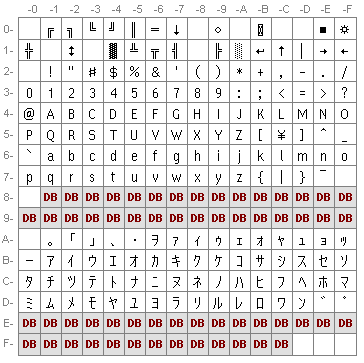
Figure 1. Codepage 932 (Japanese) – single byte character values
Like others, each CJK character set has its own codepage(s). The usual PC codepage for Japanese, for example, is codepage 932 (see Figure 1). This codepage includes the basic ASCII characters at codepoints 0x20 through 0x7E, with two differences: the backslash is replaced by the yen symbol (¥), and the tilde is replaced by the overline (¯).
As usual, the prefix “0x” is used to denote a number written in hexadecimal format. So “0x20” means “hexadecimal value 20.”
It also has, at codepoints 0xA0 through 0xDF, a small set of Japanese characters – these are known as half-width Katakana characters, and comprise the absolute minimum set of characters require to write Japanese text phonetically (in early days, these were in fact the only available means of writing in Japanese on a computer). Finally, there are a few miscellaneous symbols in the range below 0x20. All of these are single-byte characters – that is, they are all encoded using a single byte, just like the Latin and Russian text discussed in my last article.
Consequently, codepage 932 is more or less compatible with ASCII-encoded text. However, the codepage also contains a number of special codepoints: 0x81 through 0x9F, and 0xE0 through 0xFC (shown as “DB” in Figure 1). These values are used for lead bytes that indicate double-byte characters.
Under this codepage, whenever one of these lead bytes is encountered it is interpreted, not as a character by itself, but as the first byte of a double-byte character value. In other words, these bytes are read in conjunction with the next byte to form a single character.
Codepage 932 has 60 of these special codepoints, each of which (in conjunction with the following byte) allows up to an additional 256 distinct characters – although, in practice, not every possible value combination is actually used.
Figure 2. Some double-byte character values defined in codepage 932 [Larger image]
Figure 2 shows the double-byte characters for two of these codepoints: 0x82 and 0x90. As you can see, not all of the values in the second byte are used – for example, second-byte values below 0x40 are typically left undefined (for whatever reason), and a few other codepoints are left unused here and there as well.
As an example, the byte pair 0x82A0 under codepage 932 represents the Hiragana character representing an “A” vowel-sound. Under codepage 850, this would appear as two separate characters (0x82 and 0xA0):
éá
Under codepage 932, however, it should be rendered as the correct (single) Japanese character:
あ
This assumes, of course, that the current font contains a glyph for this character (otherwise it would show up as a substitution symbol, as described in my last article).
Looking at Figure 2, you may wonder what the oddly large Latin characters are for. Most CJK characters have an aspect ratio of approximately 1:1 (in other words, they fit within a square when written), and so are normally rendered in a monospaced style. Since most monospaced fonts assign only a relatively narrow rectangular region for single-byte characters, CJK characters are normally rendered to occupy two character spaces instead of one. This has the advantage of allowing extra space for these large, complex glyphs, while still allowing monospaced characters to be lined up properly.
However, mixing narrower Latin (and other single-byte) text with these extra-wide CJK characters can look a bit odd, especially within a single word (such as a name or title). It seems to be fairly common to write such mixed text using extra-wide Latin characters. This is why CJK codepages and fonts often include double-byte, double-width versions of common Latin and other single-byte characters.
Multi-byte codepages
The main multi-byte codepages which are supported by OS/2 as process codepages are listed below.
932 Japan Shift_JIS-1990 (Japanese)
949 Korea KS-Code (Korean)
950 Taiwan Big-5 (Traditional Chinese)
1381 China GB (Simplified Chinese)
1386 China GBK (Simplified Chinese)
Another Japanese codepage which is often used is 943, which is identical to 932 but can only be used as a PM codepage (in fact, 932 is simply an alias of 943, but COUNTRY.SYS only allows the former to be specified as a process codepage). There is also codepage 942, which implements the slightly older (albeit almost identical) Shift_JIS-1978 Japanese character set; it, too, is only available as a PM codepage.
The Simplified Chinese codepage 1381 is based on the GB2312 character set, and is the usual default codepage for Simplified Chinese OS/2. Codepage 1386 implements the newer GBK standard.
The Korean codepage 949 supports the KSC5601-1992 character standard (“Wansung” encoding). It should be noted that on Windows systems codepage 949 actually implements a significantly expanded Korean character set known as “Unified Hangul Code” (or “Extended Wansung”), which adds several thousand additional characters. OS/2 can be updated to support this expanded codepage 949 by replacing the file \LANGUAGE\CODEPAGE\IBM949 on the system drive with the version included in Ken Borgendale's OS/2 codepage tools.
In Part 1 of this series, I provided a brief list of the major process codepages for various locales; codepage 1381 (China GB) was inadvertently left out of this list. I apologize for the oversight.
Viewing Multi-Byte Text
So what does all this imply for the techniques I described in my last article? Well, it brings a few additional issues to the table.
DBCS-capable fonts
First, and most obviously, you need a font that supports the characters you need. This wasn't a big problem last time, when we were dealing with single-byte characters, because most of the OS/2 system fonts contain glyphs for a wide range of single-byte character sets. For instance, WarpSans, System VIO and Helv all include support for multiple Latin alphabets as well as Greek, Thai, Hebrew, Arabic, Cyrillic, and a few others. However, none of these fonts contain glyphs for any double-byte CJK characters (unless you are using one of the dedicated DBCS language versions of OS/2, which are a special case).
By itself, the OS/2 bitmap font file format does not appear to support double-byte CJK characters. DBCS versions of OS/2 such as Japanese and Chinese get around this limitation by using special font drivers: CJK character glyphs are contained in separate files, and several of the OS/2 system fonts can then load these glyphs as required.
To properly display Chinese, Japanese, or Korean characters under a single-byte language version of OS/2, you need a multilingual font that supports them. In general, this means a TrueType font—Type 1 fonts seem to be somewhat more limited in terms of supporting multiple languages, and OS/2 bitmap fonts do not normally support CJK characters at all (see the digression above).
Once again, your best bet is to use a Unicode font. As I mentioned last time, there are several Unicode fonts available which support CJK characters, and OS/2 (starting with Warp Server for e-business) even ships with some out of the box:
- Times New Roman WT *
- A Unicode version of the classic Times New Roman proportional font.
- Monotype Sans Duospace WT *
- An attractive monospaced Unicode font.
In both cases, * may be J (Japanese), K (Korean), TC (Traditional Chinese, used in Taiwan and Hong Kong) and SC (Simplified Chinese, used in mainland China). If you allow OS/2 to install the “Unicode fonts” option, the J versions will be installed (and Times New Roman WT J will also be aliased to Times New Roman MT 30, for compatibility with programs written under Warp 3 and 4).
The purpose of the Unicode standard is to allow support for all possible character sets within a single codespace. So you might wonder why the OS/2 Unicode fonts come in four different language-specific versions.
Japanese, Korean, and both forms of Chinese all use the same (Chinese-originated) ideographic characters. The Unicode standard therefore defines only a single set of CJK ideographs (which it calls Han characters) to be used by all four languages.
Between Japanese, Korean, and the two Chinese variants there are, however, stylistic differences in how some characters are customarily written. As this IBMarticle puts it:
There are four basic traditions for East Asian character shapes: traditional Chinese, simplified Chinese, Japanese, and Korean. While the Han root character may be the same for CJK languages, the glyphs in common use for the same characters may not be.
. . .
Fonts are the delivery mechanism for glyph display. This means that while Han characters have been unified, fonts can't be. To provide the glyph variations required to meet the needs of writing system differences, fonts must be specific to the system in use. Trying to use only one font guarantees that some characters won't look right to everyone.
It is important to understand that what Unicode defines is the identity of each character. The appearance of each character is left up to the font (or fonts) being used.
For this reason, IBM has provided four different versions, each “tuned” for its respective language.
I described some other useful Unicode fonts in my last article. If you have access to it, Arial Unicode MS is quite nice, especially for use in a web browser.
If you have a version of OS/2 prior to Warp Server for e-business, you are recommended to obtain the “Times New Roman MT 30” font included in certain versions of the IBM Java 1.1.8 Runtime Environment (JAVAINUF.EXE).
In fact, the same Java Runtime package will also install updated codepage (and Unicode) support on OS/2 Warp 3 and Warp 4 systems, so it is definitely a good idea to install it if you have one of these versions of OS/2.
Alternatively, OS/2 also has available some dedicated (non-Unicode) fonts for Japanese and Chinese (both forms). Once again, this applies only if you have Warp Server for e-business or later (including all versions of eComStation). They can be selected from the installation program, or installed manually later by unzipping the appropriate files from the directory \OS2IMAGE\FI\FONT on the installation CD.
| Language | Font Name | File Name | Notes |
|---|---|---|---|
| Japanese | HeiseiMincho-W3-78-TT | DFHSM-78.TTF (from DFHSM-78.ZIP) | Designed for Shift_JIS-1978 (codepage 942) |
| HeiseiMincho-W3-90-TT | DFHSM-W3.TTF (from DFHSM-W3.ZIP) | Designed for Shift_JIS-1990 (codepages 932 & 943) | |
| HeiseiKakuGothic-W5-78-TT | DFHSG-78.TTF (from DFHSG-78.ZIP) | Designed for Shift_JIS-1978 (codepage 942) | |
| HeiseiKakuGothic-W5-90-TT | DFHSG-W5.TTF (from DFHSG-W5.ZIP) | Designed for Shift_JIS-1990 (codepages 932 & 943) | |
| Simplified Chinese | 仿宋常规 | IBMFANG.TTF (from IBMFANG.ZIP) | Name shows as “À┬╦╬│ú╣µ” under codepage 850 |
| 黑体常规 | IBMHEI.TTF (from IBMHEI.ZIP) | Name shows as “║┌╠Õ│ú╣µ” under codepage 850 | |
| 楷体常规 | IBMKAI.TTF (from IBMKAI.ZIP) | Name shows as “┐¼╠Õ│ú╣µ” under codepage 850 | |
| [婳S^8壞 | IBMSONG.TTF (from IBMSONG.ZIP) | Apparently designed for GBK (codepage 1386); name shows as “[ïOS^8ë─” under codepage 850 |
|
| Traditional Chinese | 中黑體 | HEI.TTF (from HEI.ZIP) | Name shows as “ññÂ┬┼Ú” under codepage 850 |
| 標準楷體 | MOEKAI.TTF (from MOEKAI.ZIP) | Name shows as “╝ðÀÃÀó┼Ú” under codepage 850 | |
| 標準宋體 | MOESONG.TTF (from MOESONG.ZIP) | Name shows as “╝ðÀú║┼Ú” under codepage 850 |
Each of these fonts can only be used to display text in the corresponding language. Incidentally, I don't recommend trying to use them in Mozilla: in my experience, they do not work well with the Innotek Font Engine. In addition, their support of Latin text is pretty ugly (due, I think, to poor hinting); I suspect they're really intended for DBCS glyph display and nothing else.
Character substitution
There is another way to get CJK characters to display on your system, without explicitly setting the font. Presentation Manager has an obscure feature called “font association,” with which it can automatically substitute for characters that don't exist in the current font.
It works as follows. In OS2.INI there is a section called PM_SystemFonts. If this section contains a key called PM_AssociateFont which specifies the name of an installed font, then whenever Presentation Manager encounters a character which doesn't exist in the current font it will attempt to substitute the corresponding glyph from the specified font instead.

Figure 3. Unsupported characters
Say, for instance, that we want to display the string “Japanese (日本語)”, in a user interface that is currently using the System Proportional font. This font does not support any of the Japanese characters used in this string, so—once we switch the codepage to 932 or 943—it would normally display with substitution symbols instead, as shown in Figure 3.
However, let's say we define the PM_AssociateFont key [in os2.ini] to use the Japanese font HeiseiMincho-W3-90-TT. Any INI file editor can be used, including the built-in OS/2 Registry Editor, as shown in Figure 4.
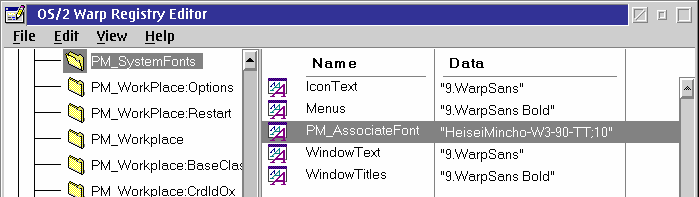
Figure 4. The PM_AssociateFont key [Larger image]
In this example, the value we assign to PM_AssociateFont is HeiseiMincho-W3-90-TT;10. Placing “;10” at the end of the font name seems to be necessary. (It may refer to the font size in some way; I am not entirely sure what the purpose of doing this is, however, since the substituted glyphs are sized to match that of the current font anyway.)
The system must be rebooted for this setting to take effect.

Figure 5. Unsupported characters with association active
Now, when we try to display the same GUI text again (using codepage 932, of course), it should display with the missing characters substituted in from the Japanese font, as shown in Figure 5.
This technique is not perfect. Presentation Manager seems to be quite picky about the font used; in my experience, it does not accept Unicode fonts (not even the ones included with OS/2). In general, you should use one of the OS/2 fonts listed in Table 1. This means, unfortunately, that you can only use this technique for one specific language or character set.
In addition, this technique only works for text in graphical (Presentation Manager) user interfaces.
Changing the codepage
In addition to having the right font, we also have to change the codepage to render the characters correctly. The basic principle is the same as in my last article, but there are some new issues involved.
Changing the PM codepage
For Presentation Manager applications, you can set the PM codepage using the CPPal utility (or through the application itself, if it supports it), as I described last time. Unfortunately, this technique doesn't work quite as smoothly with multi-byte codepages as it does with single-byte ones.
The problem arises when you start the application under a single-byte process codepage (as defined in CONFIG.SYS). When you do this, the application's GUI controls expect to be dealing with single-byte text containing standard-width characters; suddenly switching to a multi-byte PM codepage in mid-stream is not something they were designed to handle.

Figure 6. Changing the PM codepage with MLE controls [Larger image]
What happens is that PM controls which are designed to support direct text editing—entry field and MLE (editor) controls in particular—get confused when trying render double-width, double-byte characters. The exact manifestation of these problems seems to vary depending on the font being used. When using a monospaced Unicode font like Monotype Sans Duospace WT J, text may display more-or-less correctly, but text input is likely to be thoroughly messed up. When using a proportional font, a non-Unicode monospaced font, or any font in conjunction with PM_AssociateFont substitution, characters will likely end up being drawn partially on top of one another – resulting in an illegible tangle of overlapping characters. In both cases, cursor movement and positioning is likely to be erratic.
Figures 6 and 7 show the README.TXT file from the Japanese MCP2 CD-ROM open in an MLE-based text editor (AE). In both cases, the editor was initially opened under codepage 850 (a single-byte codepage), and then the PM codepage was set to codepage 943 (a multi-byte Japanese codepage identical to codepage 932).
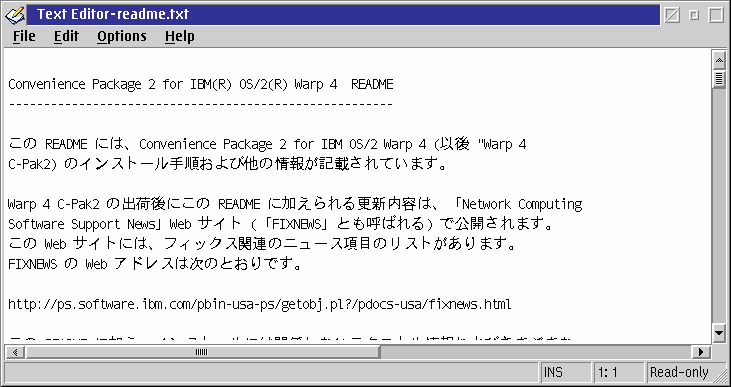
Figure 7. Changing PM codepage with MLE controls (using a monospaced Unicode font) [Larger image]
In Figure 6, the editor is using its default (bitmap) font, and is relying on PM_AssociateFont glyph substitution to display the Japanese characters. In Figure 7, the editor font has been set to the monospaced Unicode font Monotype Sans Duospace WT J.
As you can see, the double-byte characters in Figure 6 are overlapping and unreadable. The characters display correctly in Figure 7, but cursor positioning (not shown) does not work properly. If you examine Figure 7, you notice that the horizontal scrollbar is enabled, even though the text fits entirely within the available horizontal space; this is another symptom of the MLE control failing to properly calculate character widths.
As it happens, static controls such as buttons and text labels do not seem to have this trouble, and neither do listboxes or containers. This is presumably because these controls are designed to simply display text, rather than allow it to be edited.
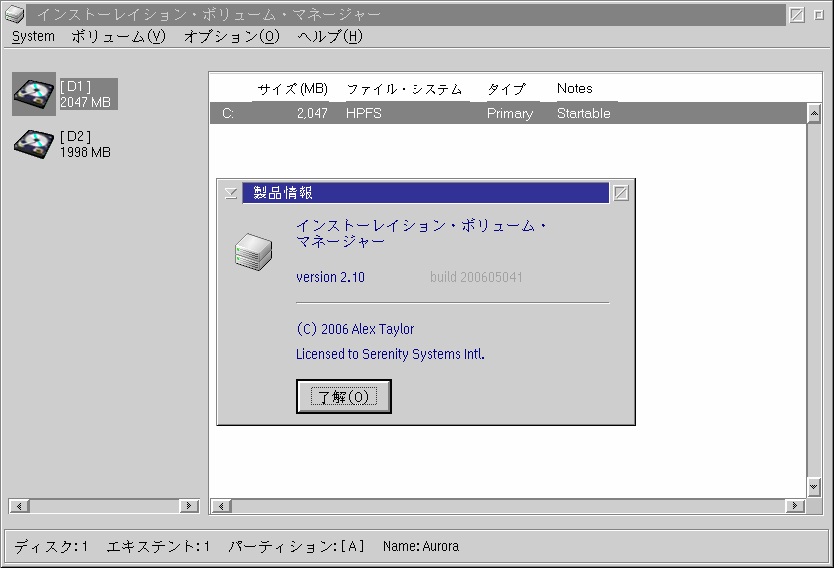
Figure 8. Changing PM codepage with static controls [Larger image]
Figure 8 illustrates how these static controls are capable of displaying multi-byte text correctly. Again, the program was run under a process codepage of 850, and then the PM codepage was changed to 943 using CPPal (font association is active).
Changing the process codepage
These problems can generally be avoided by running the program under a multi-byte process codepage from the start. Of course, this does require you to have a multi-byte codepage configured as either your primary or secondary codepage in CONFIG.SYS.
Since I work with CJK text fairly often, my CONFIG.SYS file has the following:
CODEPAGE=850,932
This lets me use Japanese text in a Presentation Manager application by running CHCP 932 in an OS/2 window before I start the program. Since the program is initialized under a multi-byte codepage right from the start, the display problems described above do not occur.
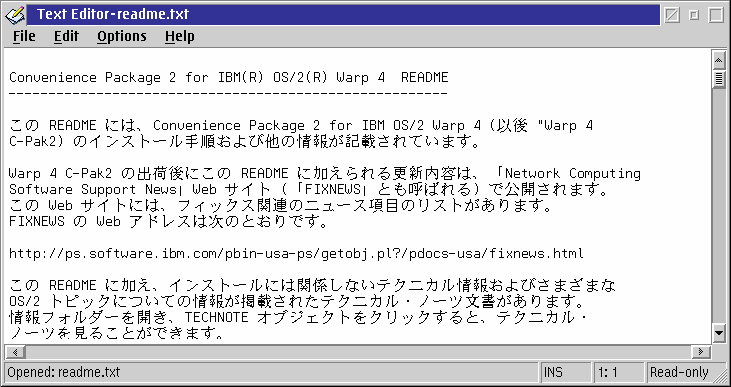
Figure 9. Using a DBCS process codepage [Larger image]
Returning to the previous example, Figure 9 shows the same Japanese text file open in the AE text editor. This time, I ran AE with the process codepage set to 932 in advance. AE is using my customary bitmap font, with glyph substitution from “HeiseiMincho-W3-90-TT” enabled using PM_AssociateFont. As you can see, the characters display correctly, and even cursor movement behaves as it should.
The nice thing about this technique is that it allows you to subsequently change the PM codepage to various other multi-byte codepages, and have the double-byte characters for those codepages render properly as well. For instance, I can start a GUI program under codepage 932 (Japanese), then use CPPal to change the PM codepage to 950 (Traditional Chinese), and all the PM controls continue to handle double-byte characters properly. It seems that the important thing is to start from a multi-byte process codepage—any multi-byte process codepage—and you can then change the PM codepage to various other multi-byte codepages without running into the problems described in the previous section.
I'm not actually sure if it works with every CJK codepage, but I have successfully used this technique to switch back and forth between Japanese and Chinese, as described.
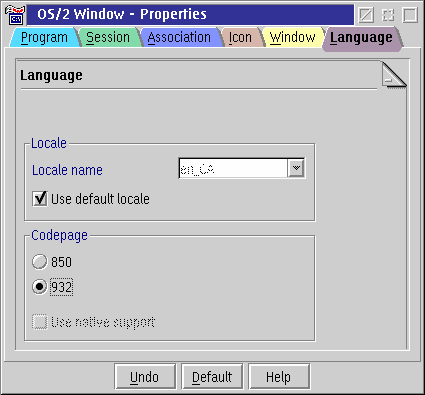
Figure 10. Setting a program object's default codepage
For this reason, if you habitually work with text or programs containing double-byte characters, it isn't a bad idea to keep your secondary codepage (in CONFIG.SYS) set to whichever multi-byte codepage you use most often. You can then display double-byte text inside a Presentation Manager application by running it from a command prompt whose process codepage is set to that secondary codepage.
Under OS/2 Warp Server for e-business or eComStation/MCP with the very latest FixPaks, you can set up a dedicated program object for this purpose. Simply create a new program object for the application in question (or an OS/2 command prompt object for the more general case), then open its properties notebook and go to the Language tab. As Figure 10 shows, you can use this page to change the default process codepage to your secondary codepage (in this example, codepage 932). Now, whenever this program or command prompt is opened, it always starts out in codepage 932.
It's important to note that even if you switch to a multi-byte process codepage in a command prompt (whether through CHCP or the Language tab), you can still only display multi-byte CJK text within graphical Presentation Manager programs started from that command prompt. You cannot use this technique to display CJK text in the command prompt itself (unless you are actually running a DBCS version of OS/2): the text-mode fonts used by OS/2 quite simply lack the necessary character support. (In most cases, you just see illegible garbage displayed in place of the CJK characters; however, I have occasionally experienced hangs or crashes. For this reason, I recommend that you don't even try it.)
KShell
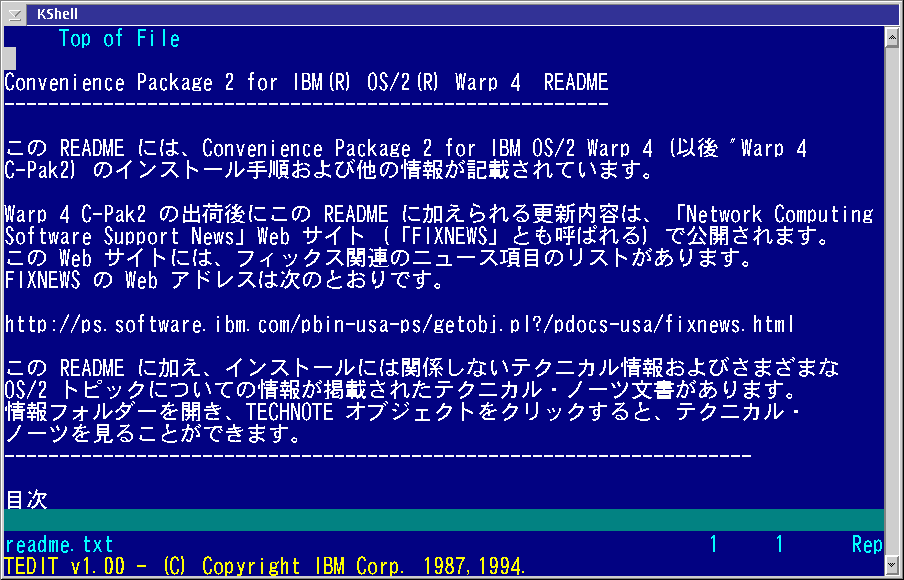
Figure 11. KShell [Larger image]
For people who need to view CJK characters directly from a command prompt, there is a nifty little program by KO Myung-Hun called KShell. KShell redirects VIO output into a special command prompt that supports multi-byte codepages and fonts under SBCS versions of OS/2. See Figure 11, which once again shows README.TXT from Japanese MCP2, this time open in the TEDIT editor.
KShell only has two configurable options: the codepage and the font. Both are accessed via the system menu control in the top left corner. In my experience, you generally have to exit and restart KShell after changing either setting for it to take effect properly.
KShell isn't perfect. For one thing, it has limited clipboard support. I've also occasionally had it fail to start properly (in which case only rebooting would get it working again). However, it can be an extremely useful program.
The font shown in Figure 11 is HeiseiKakuGothic-W5-90-TT, which is admittedly quite ugly. If you use KShell, you'll probably want to find some better-looking ones. For Japanese, I quite like the free kochi-substitute fonts, which look pretty decent in conjunction with the Innotek Font Engine. KShell does not, unfortunately, work well with Monotype Sans Duospace WT J.
{kind=link}
Mozilla
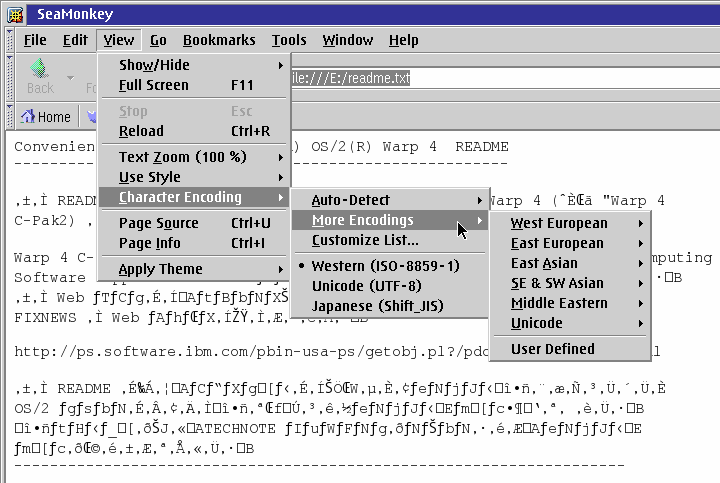
Figure 12. Changing the character set in Mozilla browsers [Larger image]
Have I confused or intimidated you enough yet? Well, I'll finish up on a slightly simpler note. If all you want to do is view some text file or other which contains multi-byte text, you don't really have to jump through any of the hoops I've just described. If you have a Mozilla browser installed (Mozilla suite, SeaMonkey, IBM Web Browser, or Firefox), you can use it to view text files in almost any character set (single- or multi-byte), and it takes care of the codepage manipulation itself.
You probably have to tell Mozilla what character set to use, of course. Unlike HTML documents, plain-text files don't contain embedded information about what character set they're encoded in. Whichever Mozilla browser you are using, you can use the View > Character Encoding menu to tell Mozilla which character set the current document should be viewed in. (See Figure 12, which once again shows README.TXT from Japanese MCP2, this time being viewed in SeaMonkey.)
You also need to make sure that character set is using an appropriate font. This is configured in much the same way in all of the various Mozilla browsers (although the exact location and layout of the dialogs varies somewhat). The font configuration dialog should have a drop-down list which specifies the language for which fonts are being configured. For each language, you must choose fonts which contain support for that language's character set(s).
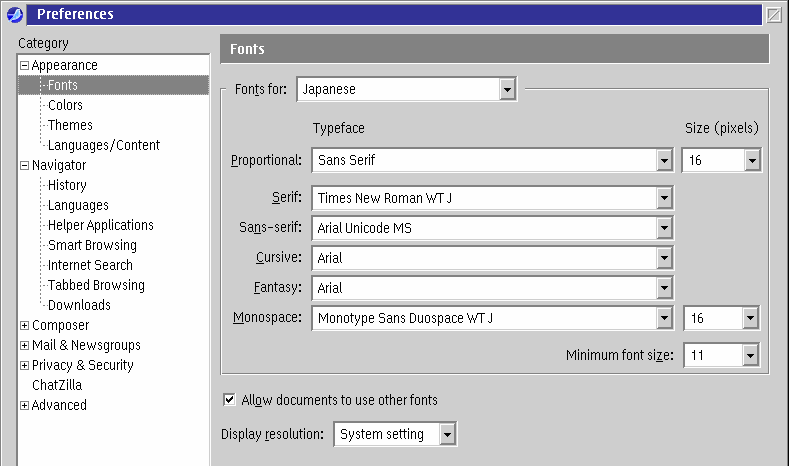
Figure 13. Configuring fonts in SeaMonkey [Larger image]
Figure 13 shows the font configuration dialog in SeaMonkey. In this example, the fonts for Japanese are being configured. With this configuration, I can switch the character encoding (as per Figure 12) to Japanese, and the contents should display correctly. Figure 14 shows the final result.

Figure 14. Correct display of a Japanese text file in SeaMonkey [Larger image]
Closing Remarks
By this point, I hope that I've given pretty good coverage to the issue of dealing with files and user interfaces that use incompatible character sets. It's not a trivial business, but you can generally cope – with the help of a few simple tools and techniques.
One thing I haven't covered in much detail so far is the issue of e-mail and newsgroup messages. Again, the Mozilla products generally take care of this for you; however, if you use different e-mail or Usenet software, you might find yourself at a loss when dealing with different character sets. Hopefully I'll talk about this in the future.
And then, of course, there's Unicode, a topic which can fill several books all by itself. Maybe I'll have an opportunity to touch on that as well.
Anyway, until next time. . . good luck!